- Very simple api
- Right api for the right job
- About Number
- Performance is optional
- Object binding styles
- Wrapper & Unwrapper
- Validation
- Collection and generics
- Lazy is an option
- Stream parsing
- Service Provider Interface (SPI)
Very simple api
deserialize
Any obj = JsonIterator.deserialize("[1,2,3]");
System.out.println(obj.get(2));
int[] array = JsonIterator.deserialize("[1,2,3]", int[].class);
System.out.println(array[2]);
just one static method, can not be more simple
serialize
System.out.println(JsonStream.serialize(new int[]{1,2,3}));
just one static method, can not be more simple
Right api for the right job
Jsoniter come with three api for different parsing job:
- iterator-api: when input is large
- bind-api: bind value to object
- any-api: lazy parsing large object
And you can mix and match
bind-api + any-api
public class ABC {
public Any a; // lazy parsed
}
JsonIterator iter = JsonIterator.parse("{'a': {'b': {'c': 'd'}}}".replace('\'', '"'));
ABC abc = iter.read(ABC.class);
System.out.println(abc.a.get("b", "c"));
when certain field do not want to bind eagerly, we can parse them later.
iterator-api + bind-api
public class User {
public int userId;
public String name;
public String[] tags;
}
JsonIterator iter = JsonIterator.parse("[123, {'name': 'taowen', 'tags': ['crazy', 'hacker']}]".replace('\'', '"'));
iter.readArray();
int userId = iter.readInt();
iter.readArray();
User user = iter.read(User.class);
user.userId = userId;
iter.readArray(); // end of array
System.out.println(user);
when using itrator, but do not want to bind field by field
any-api + bind-api
String input = "{'numbers': ['1', '2', ['3', '4']]}".replace('\'', '"');
String[] array = JsonIterator.deserialize(input).get("numbers", 2).to(String[].class);
after you extracted value from Any, then you can bind it to object using bind-api
total 6 combinations!
- iterator-api => bind-api: JsonIterator.read
- iterator-api => any-api: JsonIterator.readAny
- bind-api => iterator-api: register type decoder or property decoder
- bind-api => any-api: use
Anyas data type - any-api => bind-api: Any.as(class)
- any-api => iterator-api: JsonIterator.parse(any)
About Number
Before 0.9.21, Object.class is always decoded as Double.class. Starting from 0.9.21, Object.class is decoded to Integer/Long/BigInteger/Double when the range fit, same behavior as Jackson.
To have best performance, use int, long or double instead of Object if possible. You can control how numbers are converted by using Any instead. The raw input is captured in Any as it is, so it can convert to BigInteger, BigDecimal if you want.
Performance is optional
The default decoding/encoding mode is reflection. We can improve the performance by dynamically generated decoder/encoder class using javassist. It will generate the most efficient code for the given class of input. However, dynamically code generation is not available in all platforms, so static code generation is also provided as an option.
- reflection: the default, and support private class or field
- dynamic code generation: require javassist library dependency, public class/field only
- static code generation: also an option
Dynamic code generation
add this dependency to your project
<dependency>
<groupId>org.javassist</groupId>
<artifactId>javassist</artifactId>
<version>3.21.0-GA</version>
</dependency>
then set the mode to dynamic code generation
JsonIterator.setMode(DecodingMode.DYNAMIC_MODE_AND_MATCH_FIELD_WITH_HASH);
JsonStream.setMode(EncodingMode.DYNAMIC_MODE);
everything should still works, just much much faster
Reflection
reflection can be enabled per-class, or globally. For example, for the class
public class TestObject {
private int field1;
private int field2;
}
to bind to private field, we have to enable reflection for this type
JsoniterSpi.registerTypeDecoder(TestObject.class, ReflectionDecoderFactory.create(TestObject.class));
return iter.read(TestObject.class); // will use reflection
Or, we can set the default decoding mode to reflection
JsonIterator.setMode(DecodingMode.REFLECTION_MODE);
All features is supported using the reflection mode, just slower, but still faster than existing solutions. Here is a quick benchmark of simple object field binding:
| parser | ops/s |
|---|---|
| jackson + afterburner | 6632322.908 ± 248913.699 ops/s |
| jsoniter + reflection | 11484306.001 ± 139780.870 ops/s |
| jsoniter + codegen | 31486700.029 ± 373069.642 ops/s |
Static code generation
When you want to have maximum performance, and the platform you use can not support dynamic code generation, then you can try static codegen. To enable static codegen, 3 things need to be done:
- define what class need to be decoded or encoded using CodegenConfig
- add code generation to maven/gradle build process
- call CodegenConfig setup before use encoder or decoder
public class DemoCodegenConfig implements CodegenConfig {
@Override
public void setup() {
// register custom decoder or extensions before codegen
// so that we doing codegen, we know in which case, we need to callback
JsonIterator.setMode(DecodingMode.STATIC_MODE); // must set to static mode
JsoniterSpi.registerFieldDecoder(User.class, "score", new Decoder.IntDecoder() {
@Override
public int decodeInt(JsonIterator iter) throws IOException {
return Integer.valueOf(iter.readString());
}
});
}
@Override
public TypeLiteral[] whatToCodegen() {
return new TypeLiteral[]{
// generic types, need to use this syntax
new TypeLiteral<List<Integer>>() {
},
new TypeLiteral<Map<String, Object>>() {
},
// array
TypeLiteral.create(int[].class),
// object
TypeLiteral.create(User.class)
};
}
}
then add code generation to maven build:
<plugin>
<groupId>org.codehaus.mojo</groupId>
<artifactId>exec-maven-plugin</artifactId>
<version>1.5.0</version>
<executions>
<execution>
<id>static-codegen</id>
<phase>compile</phase>
<goals>
<goal>exec</goal>
</goals>
<configuration>
<executable>java</executable>
<workingDirectory>${project.build.sourceDirectory}</workingDirectory>
<arguments>
<argument>-classpath</argument>
<classpath/>
<argument>com.jsoniter.static_codegen.StaticCodegen</argument>
<argument>com.jsoniter.demo.DemoCodegenConfig</argument>
</arguments>
</configuration>
</execution>
</executions>
</plugin>
the generated java source code will be written out to src/main/java folder of your project. The output dir is specified by setting the workingDirectory to the project.build.sourceDirectory. The output dir can also be specified as the second argument to StaticCodeGenerator.
by setting the mode to static, dynamic code generation will not happen if the class to decode/encode does not have corresponding decoder/encoder, instead exception will be thrown.
For normal java project, please refer to demo: https://github.com/json-iterator/java/tree/master/demo
For android project, please refer to the android demo: https://github.com/json-iterator/java/tree/master/android-demo
Object binding styles
binding to object can be done using a couple of ways. Jsoniter will not force you to make fields public
Public field binding
bind the json document
{"field1":100,"field2":101}
to the class
public class TestObject {
public int field1;
public int field2;
}
bind-api is not your only option. You can also use iterator-api to do the binding manually.
iterator + switch case
TestObject obj = new TestObject();
for (String field = iter.readObject(); field != null; field = iter.readObject()) {
switch (field) {
case "field1":
obj.field1 = iter.readInt();
continue;
case "field2":
obj.field2 = iter.readInt();
continue;
default:
iter.skip();
}
}
return obj;
binding
return iter.read(TestObject.class);
read into existing object
TestObject testObject = new TestObject();
return iter.read(testObject);
Jsoniter allow reusing existing object. When you need to bind one object repeatedly, this can save the memory allocation cost.
Constructor binding
bind the json document
{"field1":100,"field2":101}
to the class
public class TestObject {
private int field1;
private int field2;
@JsonCreator
public TestObject(
@JsonProperty("field1") int field1,
@JsonProperty("field2") int field2) {
this.field1 = field1;
this.field2 = field2;
}
}
binding
It is important to mark @JsonProperty with field name, as old java version can not get parameter name by reflection.
Not only constructor binding is supported, static method working as factory method is also supported. Just mark it with @JsonCreator.
Setter Binding
bind the json document
{"field1":100,"field2":101}
to the class, using setter
public static class TestObject {
private int field1;
private int field2;
public void setField1(int field1) {
this.field1 = field1;
}
public void setField2(int field2) {
this.field2 = field2;
}
}
this is automatically supported. Multi parameter setter is also supported, but need to use annotation support.
public static class TestObject {
private int field1;
private int field2;
@JsonWrapper
public void initialize(
@JsonProperty("field1") int field1,
@JsonProperty("field2") int field2) {
this.field1 = field1;
this.field2 = field2;
}
}
return iter.read(TestObject.class);
Private field binding
bind the json document
{"field1":100,"field2":101}
to the class
public class TestObject {
private int field1;
private int field2;
}
reflection
only reflection mode support private field binding, you can register type decoder explicitly. Notice that, private field is bindable by default when using reflection decoder, you do not need to mark them as @JsonProperty to force the behavior. If you do not want the private field to be bind, you have to use @JsonIgnore to ignore them.
JsoniterSpi.registerTypeDecoder(TestObject.class, ReflectionDecoderFactory.create(TestObject.class));
return iter.read(TestObject.class);
Wrapper & Unwrapper
Wrapper
say you have this kind of object graph
public class Name {
private final String firstName;
private final String lastName;
public Name(String firstName, String lastName) {
this.firstName = firstName;
this.lastName = lastName;
}
public String getFirstName() {
return firstName;
}
public String getLastName() {
return lastName;
}
}
public class User {
private Name name;
public int score;
public Name getName() {
return name;
}
@JsonWrapper
public void setName(@JsonProperty("firstName") String firstName, @JsonProperty("lastName") String lastName) {
name = new Name(firstName, lastName);
}
}
the Name is a wrapper class. and the input is flat:
{"firstName": "tao", "lastName": "wen", "score": 100}
we can see there is no direct mapping between the json and object. this is when @JsonWrapper is helpful. essentially, it is binding to function parameters.
Unwrapper
For the same object graph, if we want to serialize it back, by default the output looks like:
JsonStream.serialize(user)
// {"score":100,"name":{"firstName":"tao","lastName":"wen"}}
Using @JsonUnwrapper we can control how to write out its member:
public class User {
private Name name;
public int score;
@JsonIgnore
public Name getName() {
return name;
}
@JsonUnwrapper
public void writeName(JsonStream stream) throws IOException {
stream.writeObjectField("firstName");
stream.writeVal(name.getFirstName());
stream.writeMore();
stream.writeObjectField("lastName");
stream.writeVal(name.getLastName());
}
@JsonWrapper
public void setName(@JsonProperty("firstName") String firstName, @JsonProperty("lastName") String lastName) {
System.out.println(firstName);
name = new Name(firstName, lastName);
}
}
then the output will be
JsonStream.serialize(user)
// {"score":100,"firstName":"tao","lastName":"wen"}
Validation
It is very common to json decode to a object, then business logic validation is applied. The json can have more fields or less fields than the object. it will be very hard for the user to catch field not set condidtion, as the information is lost after the binding. Jsoniter is one of the few json parsers has implemneted required property tracking. You can tell if a int field is 0, because there is no input, or input is 0.
Missing field
public static class TestObject {
@JsonProperty(required = true)
public int field1;
@JsonProperty(required = true)
public int field2;
@JsonProperty(required = true)
public int field3;
}
if field1 is not present in the input json, exception will be thrown.
JsonIterator iter = JsonIterator.parse("{'field2':101}".replace('\'', '"'));
return iter.read(TestObject.class);
the output is
com.jsoniter.JsonException: missing mandatory fields: [field1, field3]
at decoder.com.jsoniter.demo.MissingField.TestObject.decode_(TestObject.java)
at decoder.com.jsoniter.demo.MissingField.TestObject.decode(TestObject.java)
at com.jsoniter.JsonIterator.read(JsonIterator.java:339)
at com.jsoniter.demo.MissingField.withJsoniter(MissingField.java:85)
at com.jsoniter.demo.MissingField.test(MissingField.java:60)
If you do not want to throw exception, you can add @JsonMissingProperties to catch those fields.
public static class TestObject {
@JsonProperty(required = true)
public int field1;
@JsonProperty(required = true)
public int field2;
@JsonProperty(required = true)
public int field3;
@JsonMissingProperties
public List<String> missingFields; // will be [field1, field3]
}
Fail on unknown properties
@JsonObject(asExtraForUnknownProperties = true)
public static class TestObject2 {
public int field1;
public int field2;
}
using asExtraForUnknownProperties we can detect if the input has extra fields. Enable the annotation support:
JsonItertor iter = JsonIterator.parse("{'field1':101,'field2':101,'field3':101}".replace('\'', '"').getBytes());
return iter.read(TestObject2.class);
the error message looks like
com.jsoniter.JsonException: extra property: field3
If you do not want to throw exception, you can add @JsonExtraProperties to catch them:
@JsonObject(asExtraForUnknownProperties = true)
public static class TestObject2 {
public int field1;
public int field2;
@JsonExtraProperties
public Map<String, Any> extra; // will contain field3
}
Exclude whitelist properties
@JsonObject(asExtraForUnknownProperties = true, unknownPropertiesWhitelist = {"field2"})
public static class TestObject3 {
public int field1;
}
if the input is {"field1":100,"field2":101}, it shall pass. if the input is
{"field1":100,"field2":101,"field3":102}
exception will still be thrown. com.jsoniter.JsonException: unknown property: field3
Only fail on blacklist properties
To ensure certain fields should never appear from the input. we can set the blacklist
@JsonObject(unknownPropertiesBlacklist = {"field3"})
public static class TestObject4 {
public int field1;
}
given the input
{"field1":100,"field2":101,"field3":102}
will throw exception
com.jsoniter.JsonException: extra property: field3
Collection and generics
Collection
generic collection need to be specified using TypeLiteral
| feature | sample |
|---|---|
| array | JsonIterator.deserialize("[1,2,3,4]", int[].class) |
| list | JsonIterator.deserialize("[1,2,3,4]", new TypeLiteral<List<Integer>>(){}) |
| set | JsonIterator.deserialize("[1,2,3,4]", new TypeLiteral<Set<Integer>>(){}) |
| linked list | JsonIterator.deserialize("[1,2,3,4]", new TypeLiteral<LinkedList<Integer>>(){}) |
| list of object | JsonIterator.deserialize("[1,2,3,4]", List.class) |
| map | JsonIterator.deserialize("{\"a\":1,\"b\":2}", new TypeLiteral<Map<String, Integer>>(){}) |
collection can also be decoded using the iterator-api, for example, given the input
[1,2,3,4]
if we use binding to sum, the code looks like
int[] arr = iter.read(int[].class);
int total = 0;
for (int i = 0; i < arr.length; i++) {
total += arr[i];
}
return total;
using iterator, we can get rid of the itermediate array
int total = 0;
while (iter.readArray()) {
total += iter.readInt();
}
return total;
the performance difference is huge
| parser | ops/s |
|---|---|
| jackson | 4419446.858 ± 88015.833 ops/s |
| jsoniter + binding | 15061063.604 ± 453904.401 ops/s |
| jsoniter + iterator | 26425709.524 ± 333111.069 ops/s |
Generic field
If the generic type is specified when defining the field, its component type can be recognized
public class TestObject {
public List<Integer> values;
}
JsonIterator.deserialize("{\"values\":[1,2,3]}", TestObject.class);
Generic field type variable can also be filled by the sub-class
public class SuperClass<E> {
public List<E> values;
}
public class SubClass extends SuperClass<Integer> {
}
JsonIterator.deserialize("{\"values\":[1,2,3]}", SubClass.class);
The generic type is instantiated with proper type arguments by one of the three ways:
- TypeLiteral
- Sub-class
- Direct field definition
If the type is not specified, Object.class will be used instead.
Interface type
If the type binding to is a interface, we have to choose a proper implementation to instantiate the object. The defaults are:
| interface | impl |
|---|---|
| List | ArrayList |
| Set | HashSet |
| Map | HashMap |
Other interface types will be specified by the user.
JsoniterSpi.registerTypeImplementation(MyInterface.class, MyObject.class);
This will use MyObject.class to create object wheree MyInterface.class instance is needed. This implementation relationship can also be specified using @JsonProperty.
Lazy is an option
It is tedious to design a class to describe the schema of data. Jsoniter allow you to decode the json as an Any object, and start using it right away. The experience is very similar to PHP json_decode.
Lazy is not slow
given a larget json document
[
// many many more
{
"_id": "58659f976f045f9c69c53efb",
"index": 4,
"guid": "3cbaef3d-25ab-48d0-8807-1974f6aad336",
"isActive": true,
"balance": "$1,854.63",
"picture": "http://placehold.it/32x32",
"age": 26,
"eyeColor": "brown",
"name": "Briggs Larson",
"gender": "male",
"company": "ZOXY",
"email": "[email protected]",
"phone": "+1 (807) 588-3350",
"address": "994 Nichols Avenue, Allamuchy, Guam, 3824",
"about": "Sunt velit ullamco consequat velit ad nisi in sint qui qui ut eiusmod eu. Et ut aliqua mollit cupidatat et proident tempor do est enim exercitation amet aliquip. Non exercitation proident do duis non ullamco do esse dolore in occaecat. Magna ea labore aliqua laborum ad amet est incididunt et quis cillum nulla. Adipisicing veniam nisi esse officia dolor labore. Proident fugiat consequat ullamco fugiat. Est et adipisicing eiusmod excepteur deserunt pariatur aute commodo dolore occaecat veniam dolore.\r\n",
"registered": "2014-07-21T03:28:39 -08:00",
"latitude": -59.741245,
"longitude": -9.657004,
"friends": [
{
"id": 0,
"name": "Herminia Mcknight"
},
{
"id": 1,
"name": "Leann Harding"
},
{
"id": 2,
"name": "Marisol Sykes"
}
],
"tags": [
"ea",
"velit",
"sunt",
"fugiat",
"do",
"Lorem",
"nostrud"
],
"greeting": "Hello, Briggs Larson! You have 3 unread messages.",
"favoriteFruit": "apple"
}
// many many more
]
if we use traditional way to parse it, it will be list of hash map
List users = (List) iter.read();
int total = 0;
for (Object userObj : users) {
Map user = (Map) userObj;
List friends = (List) user.get("friends");
total += friends.size();
}
return total;
using Any, we can lazy parse it:
Any users = iter.readAny();
int total = 0;
for (Any user : users) { // array parsing triggered
total += user.getValue("friends").size(); // object parsing triggered
}
return total;
the laziness can be verified by benchmark:
| parsing style | ops/s |
|---|---|
| eager | 48510.942 ± 3891.295 ops/s |
| lazy | 65088.956 ± 5026.304 ops/s |
Any is easy
Any can get value directly from nested structure. Any can read value in the type you want, regardless the actual type in the json.
String input = "{'numbers': ['1', '2', ['3', '4']]}".replace('\'', '"');
int value = JsonIterator.deserialize(input).toInt("numbers", 2, 0); // value is 3, converted from string
you can detect if the value is present or not, by a single get
String input = "{'numbers': ['1', '2', ['3', '4']]}".replace('\'', '"');
Any any = JsonIterator.deserialize(input);
Any found = any.get("num", 100); // found is null, so we know it is missing from json
Any can be another layer
It used to be the business between “raw bytes” and “objects”. Now, we have Any which is a middle ground between them. Take a look at this example:
List<Any> users = iter.readAny().asList();
Map<String, Any> firstUser = users.get(0).asMap();
HashMap<String, Any> secondUser = new HashMap<>(firstUser);
secondUser.put("name", Any.wrap("fake"));
users.add(1, Any.wrapAnyMap(secondUser));
System.out.println(JsonStream.serialize(users));
decoding from input to list of Any, then we do some modification, then we serialize them. Every raw bytes not touched during this transformation is kept as it is, so it should be much much faster than reading everything into object form. It is as if we are manipulating the input directly, copy from one byte array to another byte array.
Here is another example:
User tom = new User();
tom.index = 1;
tom.name = "tom";
Map<String, Any> tomAsMap = Any.wrap(tom).asMap();
tomAsMap.put("age", Any.wrap(17));
System.out.println(JsonStream.serialize(tomAsMap));
the serialization is done twice. First the object is transformed into a map, then we do some processing, then the map is transformed into raw bytes. Any can be another layer, when you need it.
Fun with Any
Modify Any
Any any = JsonIterator.deserialize("{'numbers': ['1', '2', ['3', '4']]}".replace('\'', '"'));
any.get("numbers").asList().add(Any.wrap("hello"));
assertEquals("{'numbers':['1', '2', ['3', '4'],'hello']}".replace('\'', '"'), JsonStream.serialize(any))
Extract the value you want, even it is not there
any = JsonIterator.deserialize("{'error': 'failed'}".replace('\'', '"')); // not there
assertFalse(any.toBoolean("success"));
any = JsonIterator.deserialize("{'success': true}".replace('\'', '"')); // boolean type
assertTrue(any.toBoolean("success"));
any = JsonIterator.deserialize("{'success': 'false'}".replace('\'', '"')); // string type
assertFalse(any.toBoolean("success"));
Get all array elements
any = JsonIterator.deserialize("[{'score':100}, {'score':102}]".replace('\'', '"'));
assertEquals("[100,102]", JsonStream.serialize(any.get('*', "score")));
Get all object elements
any = JsonIterator.deserialize("[{'score':100}, {'score':[102]}]".replace('\'', '"'));
assertEquals("[{},{'score':102}]".replace('\'', '"'), JsonStream.serialize(any.get('*', '*', 0)));
Get object wrapped by any
any = JsonIterator.deserialize("[{'score':100}, {'score':102}]".replace('\'', '"'));
assertEquals(Long.class, any.get(0, "score").object().getClass());
Check path exists or not
any = JsonIterator.deserialize("[{'score':100}, {'score':102}]".replace('\'', '"'));
assertEquals(ValueType.INVALID, any.get(0, "score", "number").valueType());
Stream parsing
when dealing with large json input, we might want to process them in a streaming way. I found existing solution to be cumbersome to use, so jsoniter (json iterator) is invented.
given we want to parse this document, and count tags
{
"users": [
{
"_id": "58451574858913704731",
"about": "a4KzKZRVvqfBLdnpUWaD",
"address": "U2YC2AEVn8ab4InRwDmu",
"age": 27,
"balance": "I5cZ5vRPmVXW0lhhRzF4",
"company": "jwLot8sFN1hMdE4EVW7e",
"email": "30KqJ0oeYXLqhKMLDUg6",
"eyeColor": "RWXrMsO6xi9cpxPqzJA1",
"favoriteFruit": "iyOuAekbybTUeDJqkHNI",
"gender": "ytgB3Kzoejv1FGU6biXu",
"greeting": "7GXmN2vMLcS2uimxGQgC",
"guid": "bIqNIywgrzva4d5LfNlm",
"index": 169390966,
"isActive": true,
"latitude": 70.7333712683406,
"longitude": 16.25873969455544,
"name": "bvtukpT6dXtqfbObGyBU",
"phone": "UsxtI7sWGIEGvM2N1Mh0",
"picture": "8fiyZ2oKapWtH5kXyNDZJjvRS5PGzJGGxDCAk1he1wuhUjxfjtGIh6agQMbjovF10YlqOyzhQPCagBZpW41r6CdrghVfgtpDy7YH",
"registered": "gJDieuwVu9H7eYmYnZkz",
"tags": [
"M2b9n0QrqC",
"zl6iJcT68v",
"VRuP4BRWjs",
"ZY9jXIjTMR"
]
}
]
}
Tokenizer is cumbersome
https://jsonp.java.net/ is awful, it does not even have a api to skip a whole value, so I will skip that. Jackson is the only streaming parser I can find. Here is the implementation:
public int calc(JsonParser jParser) throws IOException {
int totalTagsCount = 0;
while (jParser.nextToken() != com.fasterxml.jackson.core.JsonToken.END_OBJECT) {
String fieldname = jParser.getCurrentName();
if ("users".equals(fieldname)) {
while (jParser.nextToken() != com.fasterxml.jackson.core.JsonToken.END_ARRAY) {
totalTagsCount += jacksonUser(jParser);
}
}
}
return totalTagsCount;
}
private int jacksonUser(JsonParser jParser) throws IOException {
int totalTagsCount = 0;
while (jParser.nextToken() != com.fasterxml.jackson.core.JsonToken.END_OBJECT) {
String fieldname = jParser.getCurrentName();
switch (fieldname) {
case "tags":
jParser.nextToken();
while (jParser.nextToken() != com.fasterxml.jackson.core.JsonToken.END_ARRAY) {
totalTagsCount++;
}
break;
default:
jParser.nextToken();
jParser.skipChildren();
}
}
return totalTagsCount;
}
looks not bad actually. the problem is the api is a tokenizer. You will get a token and decide what to do with it. If you did not handle the all cases for the token, then when the input is not what you want, it is very hard to debug.
Iterator to rescue
Same logic implemented using jsoniter iterator-api:
public int calc(JsonIterator iter) throws IOException {
int totalTagsCount = 0;
for (String field = iter.readObject(); field != null; field = iter.readObject()) {
switch (field) {
case "users":
while (iter.readArray()) {
for (String field2 = iter.readObject(); field2 != null; field2 = iter.readObject()) {
switch (field2) {
case "tags":
while (iter.readArray()) {
iter.skip();
totalTagsCount++;
}
break;
default:
iter.skip();
}
}
}
break;
default:
iter.skip();
}
}
return totalTagsCount;
}
if we change the input a little bit
{
"users": [
{
// ...
"tags": {
"tag1": "M2b9n0QrqC",
"tag2": "zl6iJcT68v",
"tag3": "VRuP4BRWjs",
"tag4": "ZY9jXIjTMR"
}
}
]
}
the error message is comprehensible:
com.jsoniter.JsonException: readArray: expect [ or , or n or ], but found: {, head: 1010, peek: "tags": {, buf: {
Service Provider Interface (SPI)
Extensibility is built-in from day one. I hate sea of feature flags. Callback interface is always preferred if applicable. Feature set is kept as minimal. If one thing can be done from user code, I will not add that feature. If adding one feature will have performance penalty for everybody, it will not be introduced.
Architecture
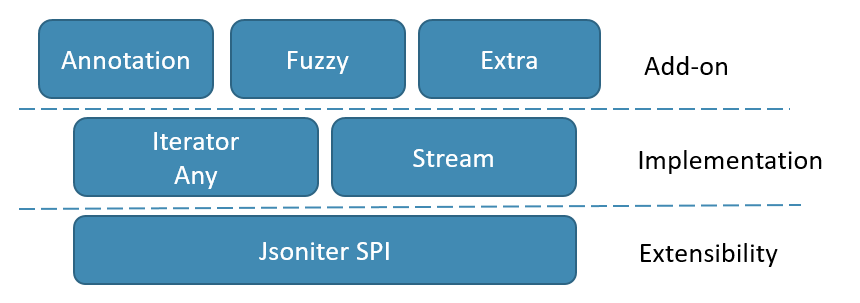
The architecture of Jsoniter is 3 layered.
- Bottom of the abstraction is service provider interface. It defines things like Encoder/Decoder or ClassDescriptor.
- Core is the implementation. Stream is the encoding part, should never reference Iterator/Any. Iterator/Any is the decoding part, iterator is forward only, Any is a wrapper of iterator to provide random access.
- Top are addons. Especially the annotation support is addon. Anything annotation support can be implemented by you using SPI. There is even support to adapt Jackson annotation so that you can keep model class unchanged.
The goal here is to quickly demonstrate what is possible with the SPI. For detailed usage guide, please read the source code.
Extend without Extension
Everything can be done with Extension. However, there are shortcuts
- registerTypeDecoder: specify how to decode a type
- registerPropertyDecoder: control how field of a specific class to be decoded
- registerTypeEncoder: specify how to encode a type
- registerPropertyEncoder: control how field of a specific class to be encoded
- registerTypeImplementation: choose the concrete class for abstract class or interface
Extension can customize everything
public interface Extension {
Type chooseImplementation(Type type);
boolean canCreate(Class clazz);
Object create(Class clazz);
Decoder createDecoder(String cacheKey, Type type);
Encoder createEncoder(String cacheKey, Type type);
void updateClassDescriptor(ClassDescriptor desc);
}
You can customize
- type encoding/decoding, just like registerTypeEncoder, registerTypeDecoder
- control how instance being created, integrate your favorite dependency injection tool
- choose implementation, just like registerTypeImplementation
- updateClassDescriptor, which will be explained below
public class ClassDescriptor {
public Class clazz;
public Map<String, Type> lookup;
public ConstructorDescriptor ctor;
public List<Binding> fields;
public List<Binding> setters;
public List<Binding> getters;
public List<WrapperDescriptor> wrappers;
public List<Method> unWrappers;
public boolean asExtraForUnknownProperties;
public Binding onMissingProperties;
public Binding onExtraProperties;
}
Class descriptor is a middle tier between object encoding/decoding code (both codegen and reflection mode) and real object layout. For example, rename field is done through change the fields List<Binding>.
public class Binding {
// input
public final Class clazz;
public final TypeLiteral clazzTypeLiteral;
public Annotation[] annotations;
public Field field; // obj.XXX
public Method method; // obj.setXXX() or obj.getXXX()
public boolean valueCanReuse;
// input/output
public String name;
public Type valueType;
public TypeLiteral valueTypeLiteral;
// output
public String[] fromNames; // for decoder
public String[] toNames; // for encoder
public Decoder decoder;
public Encoder encoder;
public boolean asMissingWhenNotPresent;
public boolean asExtraWhenPresent;
public boolean isNullable = true;
public boolean isCollectionValueNullable = true;
public boolean shouldOmitNull = true;
// then this property will not be unknown
// but we do not want to bind it anywhere
public boolean shouldSkip;
// attachment, used when generating code or reflection
public int idx;
public long mask;
}
by setting the fromNames or toNames we can change how to map the field to/from JSON. Everything annotation supported is via extension, which means you can always customize the object binding without chaning the class definition itself.
There are several predefined extension in “extra” package
- Base64Support
- JdkDatetimeSupport
- NamingStrategySupport
- PreciseFloatSupport
Instead of feature flags in the core implementation, using extension we can still provide some functionality without performance comprise.