- 超简单的 api
- 给不同的任务选择不同的 api
- 关于数字类型
- 极致性能需要代码生成
- 对象绑定的多种姿势
- Wrapper & Unwrapper
- 数据验证
- 集合和泛型
- 懒惰是一种美德
- 流式解析
- Service Provider Interface (SPI)
超简单的 api
反序列化
Any obj = JsonIterator.deserialize("[1,2,3]");
System.out.println(obj.get(2));
int[] array = JsonIterator.deserialize("[1,2,3]", int[].class);
System.out.println(array[2]);
只有一个静态方法,没法更简单了
序列化
System.out.println(JsonStream.serialize(new int[]{1,2,3}));
就一个静态方法,真没法更简单了
给不同的任务选择不同的 api
Jsoniter 有三个不同的 api 用于不同的场合:
- iterator-api:用于处理超大的输入
- bind-api:日常最经常使用的对象绑定
- any-api:lazy 解析大对象,具有 PHP Array 一般的使用体验
而且你还能自由混搭出6个组合
bind-api + any-api
public class ABC {
public Any a; // lazy parsed
}
JsonIterator iter = JsonIterator.parse("{'a': {'b': {'c': 'd'}}}".replace('\'', '"'));
ABC abc = iter.read(ABC.class);
System.out.println(abc.a.get("b", "c"));
对于某些字段不想立刻被解析,可以用 Any 保存起来,用到的时候再延迟解析
iterator-api + bind-api
public class User {
public int userId;
public String name;
public String[] tags;
}
JsonIterator iter = JsonIterator.parse("[123, {'name': 'taowen', 'tags': ['crazy', 'hacker']}]".replace('\'', '"'));
iter.readArray();
int userId = iter.readInt();
iter.readArray();
User user = iter.read(User.class);
user.userId = userId;
iter.readArray(); // end of array
System.out.println(user);
使用 iterator 做流式解析的时候,一个个绑定字段很麻烦,可以局部使用一下 bind-api
any-api + bind-api
String input = "{'numbers': ['1', '2', ['3', '4']]}".replace('\'', '"');
String[] array = JsonIterator.deserialize(input).get("numbers", 2).to(String[].class);
从 Any 里面抽取出来了值,然后还能用 bind-api 绑定到对象上
总共 6 种组合!
- iterator-api => bind-api: JsonIterator.read
- iterator-api => any-api: JsonIterator.readAny
- bind-api => iterator-api: register type decoder or property decoder
- bind-api => any-api: use
Anyas data type - any-api => bind-api: Any.as(class)
- any-api => iterator-api: JsonIterator.parse(any)
关于数字类型
在 0.9.21 之前,Object.class 总被反序列化成 Double.class。从 0.9.21 开始,Object.class 会在范围允许的情况下选择 Integer/Long/BigInteger/Double,和 jackson 的行为一样。
为了有最好的性能,尽量选择 int,long 或者 double 这样的具体类型。如果你希望控制数字是怎么被转换的,请使用 Any。因为原始的输入被捕捉到了 Any 对象内,所以你可以选择转换成 BigInteger 或者 BigDecimal。
极致性能需要代码生成
缺省的编解码的方式是反射。如果用 javassist 实现动态代码生成的话性能可以成倍提升。它可以给对应的输入的 class 生成定制化的高效代码。然而动态代码生成在某些平台上不可用,所以静态代码生成的用法也是支持的。
- 反射:默认选项,零依赖,支持私有类和成员
- 动态代码生成:需要 javassist 库,仅支持公有类和成员
- 静态代码生成:麻烦一点,但是也可以这么用
动态代码生成
把这个依赖添加到你的项目里
<dependency>
<groupId>org.javassist</groupId>
<artifactId>javassist</artifactId>
<version>3.21.0-GA</version>
</dependency>
然后把模式设置为动态代码生成
JsonIterator.setMode(DecodingMode.DYNAMIC_MODE_AND_MATCH_FIELD_WITH_HASH);
JsonStream.setMode(EncodingMode.DYNAMIC_MODE);
所有的功能应该都能正常工作的,而且要快很多
反射
反射可以给具体的某个 class 启用,也可以全局开启。比如,对于这个 class
public class TestObject {
private int field1;
private int field2;
}
为了把值绑定到私有成员上,我们必须对这个类启用反射
JsoniterSpi.registerTypeDecoder(TestObject.class, ReflectionDecoderFactory.create(TestObject.class));
return iter.read(TestObject.class); // will use reflection
或者我们也可以把默认的模式设置为反射
JsonIterator.setMode(DecodingMode.REFLECTION_MODE);
所有的特性在反射模式下都是支持的,只是比代码生成的要慢一点。但是还是比其他的解决方案快很多,这里是一个简单的对象多字段绑定的性能评测:
| parser | ops/s |
|---|---|
| jackson + afterburner | 6632322.908 ± 248913.699 ops/s |
| jsoniter + reflection | 11484306.001 ± 139780.870 ops/s |
| jsoniter + codegen | 31486700.029 ± 373069.642 ops/s |
静态代码生成
如果你想要最好的性能,但是你使用的平台又无法支持动态代码生成的时候,你可以选择静态代码生成。要启用静态代码生成,需要完成三件事情:
- 通过 CodegenConfig 提前定义哪些 class 是需要编解码的
- 把代码生成加入到 build 的过程中,比如 maven/gradle
- 在使用前,调用 CodegenConfig 的 setup 方法
首先我们来定义哪些class是需要编解码的
public class DemoCodegenConfig implements CodegenConfig {
@Override
public void setup() {
// register custom decoder or extensions before codegen
// so that we doing codegen, we know in which case, we need to callback
JsonIterator.setMode(DecodingMode.STATIC_MODE); // must set to static mode
JsoniterSpi.registerFieldDecoder(User.class, "score", new Decoder.IntDecoder() {
@Override
public int decodeInt(JsonIterator iter) throws IOException {
return Integer.valueOf(iter.readString());
}
});
}
@Override
public TypeLiteral[] whatToCodegen() {
return new TypeLiteral[]{
// generic types, need to use this syntax
new TypeLiteral<List<Integer>>() {
},
new TypeLiteral<Map<String, Object>>() {
},
// array
TypeLiteral.create(int[].class),
// object
TypeLiteral.create(User.class)
};
}
}
然后我们在 maven 中添加代码生成的调用:
<plugin>
<groupId>org.codehaus.mojo</groupId>
<artifactId>exec-maven-plugin</artifactId>
<version>1.5.0</version>
<executions>
<execution>
<id>static-codegen</id>
<phase>compile</phase>
<goals>
<goal>exec</goal>
</goals>
<configuration>
<executable>java</executable>
<workingDirectory>${project.build.sourceDirectory}</workingDirectory>
<arguments>
<argument>-classpath</argument>
<classpath/>
<argument>com.jsoniter.static_codegen.StaticCodegen</argument>
<argument>com.jsoniter.demo.DemoCodegenConfig</argument>
</arguments>
</configuration>
</execution>
</executions>
</plugin>
产生的java代码会被写到你项目的 src/main/java 目录,作为你的代码的一部分。输出目录是通过workingDirectory来指定的。如果你不想改workingDirectory,也可以传递第二个参数给StaticCodeGenerator。
把模式设置为 static 之后,动态代码生成就不会被自动触发了。如果对应的类没有预先生成的编解码代码,异常会被抛出。
普通的 Java 项目,参见: https://github.com/json-iterator/java/tree/master/demo
Android 项目,参见: https://github.com/json-iterator/java/tree/master/android-demo
对象绑定的多种姿势
Java程序员是矫情的。相比 golang 的纯真朴素,java 里给一个对象赋值的方式不要太多了。Jsoniter 入乡随俗,不会强制只支持 field 绑定的方式的。以下是所有的对象绑定可能:
公有 field 绑定
给定这样的文档
{"field1":100,"field2":101}
绑定到这个 class 上
public class TestObject {
public int field1;
public int field2;
}
bind-api 好用,但是不是唯一的选择。你也可以使用 iterator-api 来手工完成绑定
iterator + switch case
TestObject obj = new TestObject();
for (String field = iter.readObject(); field != null; field = iter.readObject()) {
switch (field) {
case "field1":
obj.field1 = iter.readInt();
continue;
case "field2":
obj.field2 = iter.readInt();
continue;
default:
iter.skip();
}
}
return obj;
binding
如果用 bind-api,就可以简化为一行代码:
return iter.read(TestObject.class);
read into existing object
TestObject testObject = new TestObject();
return iter.read(testObject);
Jsoniter 深圳允许你复用已有的对象,把值直接绑定上去。当你需要反复地绑定对象的时候,这可以节省内存分配的时间。
构造函数绑定
绑定这个文档
{"field1":100,"field2":101}
到 class 上
public class TestObject {
private int field1;
private int field2;
@JsonCreator
public TestObject(
@JsonProperty("field1") int field1,
@JsonProperty("field2") int field2) {
this.field1 = field1;
this.field2 = field2;
}
}
binding
必须把参数用 @JsonProperty 标记,因为旧的 java 版本无法通过反射获得参数名。
@JsonCreator 不仅仅支持构造函数,静态函数充当工厂方法也是可以的。
Setter 绑定
绑定这个文档
{"field1":100,"field2":101}
绑定到使用 setter 的这个 class 上
public static class TestObject {
private int field1;
private int field2;
public void setField1(int field1) {
this.field1 = field1;
}
public void setField2(int field2) {
this.field2 = field2;
}
}
这个写法是自动支持的。甚至如果 setter 有多个参数也是可以的(严格意义上来说,这就不是setter了),但是需要 annotation 的支持。
public static class TestObject {
private int field1;
private int field2;
@JsonWrapper
public void initialize(
@JsonProperty("field1") int field1,
@JsonProperty("field2") int field2) {
this.field1 = field1;
this.field2 = field2;
}
}
return iter.read(TestObject.class);
私有成员绑定
绑定这个文档
{"field1":100,"field2":101}
到这个类上
public class TestObject {
private int field1;
private int field2;
}
reflection
只有反射模式才支持私有成员的绑定。注意当使用反射的时候,无需标记 @JsonProperty,所有字段默认都会被序列化和反序列化,除非使用 @JsonIgnore 排除掉。
JsoniterSpi.registerTypeDecoder(TestObject.class, ReflectionDecoderFactory.create(TestObject.class));
return iter.read(TestObject.class);
Wrapper & Unwrapper
Wrapper
假定你有这样的一些对象
public class Name {
private final String firstName;
private final String lastName;
public Name(String firstName, String lastName) {
this.firstName = firstName;
this.lastName = lastName;
}
public String getFirstName() {
return firstName;
}
public String getLastName() {
return lastName;
}
}
public class User {
private Name name;
public int score;
public Name getName() {
return name;
}
@JsonWrapper
public void setName(@JsonProperty("firstName") String firstName, @JsonProperty("lastName") String lastName) {
name = new Name(firstName, lastName);
}
}
Name 是一个封装类,你不希望这个封装类被json绑定给影响。但是输入字段是平铺的
{"firstName": "tao", "lastName": "wen", "score": 100}
我们可以看到json和对象在结构上是不匹配的,这时就要@JsonWrapper来救场了。本质上来说,它就是把值绑定到函数参数上,而不是绑定到对象上。
Unwrapper
对于同样的对象图,如果我们想要把对象重新序列化为json。默认这个输出就变成了:
JsonStream.serialize(user)
// {"score":100,"name":{"firstName":"tao","lastName":"wen"}}
使用 @JsonUnwrapper 我们可以控制对象的成员是如何被写出到json的:
public class User {
private Name name;
public int score;
@JsonIgnore
public Name getName() {
return name;
}
@JsonUnwrapper
public void writeName(JsonStream stream) throws IOException {
stream.writeObjectField("firstName");
stream.writeVal(name.getFirstName());
stream.writeMore();
stream.writeObjectField("lastName");
stream.writeVal(name.getLastName());
}
@JsonWrapper
public void setName(@JsonProperty("firstName") String firstName, @JsonProperty("lastName") String lastName) {
System.out.println(firstName);
name = new Name(firstName, lastName);
}
}
这样搞之后,输出的json又重新变成了平铺的了:
JsonStream.serialize(user)
// {"score":100,"firstName":"tao","lastName":"wen"}
数据验证
非常常见的做法是先把 json 绑定到对象,然后对对象进行业务上的合法性验证。json 可能比对象的字段要多或者要少。在做合法性验证的时候,要去推测当时 json 的实际情况是如何的比较难做。因为信息在绑定的过程中就丢失了。Jsoniter 是为数不多把必填字段跟踪实现了的 json 解析器。你拿到一个int字段的时候,如果值为0,可以知道是因为 json 里没有制定,默认值的0,还是 json 输入里填的就是0。
必填字段
public static class TestObject {
@JsonProperty(required = true)
public int field1;
@JsonProperty(required = true)
public int field2;
@JsonProperty(required = true)
public int field3;
}
如果 field1 没有出现在 json 文档里,异常会被抛出。
JsonIterator iter = JsonIterator.parse("{'field2':101}".replace('\'', '"'));
return iter.read(TestObject.class);
异常的消息是
com.jsoniter.JsonException: missing mandatory fields: [field1, field3]
at decoder.com.jsoniter.demo.MissingField.TestObject.decode_(TestObject.java)
at decoder.com.jsoniter.demo.MissingField.TestObject.decode(TestObject.java)
at com.jsoniter.JsonIterator.read(JsonIterator.java:339)
at com.jsoniter.demo.MissingField.withJsoniter(MissingField.java:85)
at com.jsoniter.demo.MissingField.test(MissingField.java:60)
如果你不希望抛异常,可以提供一个标记了 @JsonMissingProperties 的字段来装这些缺失的必填字段的名字
public static class TestObject {
@JsonProperty(required = true)
public int field1;
@JsonProperty(required = true)
public int field2;
@JsonProperty(required = true)
public int field3;
@JsonMissingProperties
public List<String> missingFields; // will be [field1, field3]
}
处理未知属性
@JsonObject(asExtraForUnknownProperties = true)
public static class TestObject2 {
public int field1;
public int field2;
}
把 asExtraForUnknownProperties 设置为 true 之后,多余的字段出现的话就会报错。当然还是要开启 annotation 的支持
JsonItertor iter = JsonIterator.parse("{'field1':101,'field2':101,'field3':101}".replace('\'', '"').getBytes());
return iter.read(TestObject2.class);
错误消息看起来是这样的
com.jsoniter.JsonException: extra property: field3
如果你不想要抛出异常,可以提供一个标记了 @JsonExtraProperties 的字段来保存这些未知的属性:
@JsonObject(asExtraForUnknownProperties = true)
public static class TestObject2 {
public int field1;
public int field2;
@JsonExtraProperties
public Map<String, Any> extra; // will contain field3
}
map 的值是 Any 类型的,其内容是 lazy 解析的。意味着这里其实只是一个 byte 数组而已。
未知属性的白名单
@JsonObject(asExtraForUnknownProperties = true, unknownPropertiesWhitelist = {"field2"})
public static class TestObject3 {
public int field1;
}
如果输入是 {"field1":100,"field2":101},它可以通过。如果输入是
{"field1":100,"field2":101,"field3":102}
这样的输入就会抛异常 com.jsoniter.JsonException: unknown property: field3
未知属性的黑名单
如果要保证输入里一定没有指定的字段,我们可以设置黑名单
@JsonObject(unknownPropertiesBlacklist = {"field3"})
public static class TestObject4 {
public int field1;
}
给定这样的输入
{"field1":100,"field2":101,"field3":102}
则会抛异常
com.jsoniter.JsonException: extra property: field3
集合和泛型
集合
泛型的集合对象需要使用 TypeLiteral 的方式来指定其值的类型
| feature | sample |
|---|---|
| array | JsonIterator.deserialize("[1,2,3,4]", int[].class) |
| list | JsonIterator.deserialize("[1,2,3,4]", new TypeLiteral<List<Integer>>(){}) |
| set | JsonIterator.deserialize("[1,2,3,4]", new TypeLiteral<Set<Integer>>(){}) |
| linked list | JsonIterator.deserialize("[1,2,3,4]", new TypeLiteral<LinkedList<Integer>>(){}) |
| list of object | JsonIterator.deserialize("[1,2,3,4]", List.class) |
| map | JsonIterator.deserialize("{\"a\":1,\"b\":2}", new TypeLiteral<Map<String, Integer>>(){}) |
集合也可以使用 iterator-api 来手工解析,比如对于这样的输入
[1,2,3,4]
如果我们想要求和,可以写这样的代码来实现:
int[] arr = iter.read(int[].class);
int total = 0;
for (int i = 0; i < arr.length; i++) {
total += arr[i];
}
return total;
通过iterator可以避免中间对象的存在:
int total = 0;
while (iter.readArray()) {
total += iter.readInt();
}
return total;
性能差别也是很大的
| parser | ops/s |
|---|---|
| jackson | 4419446.858 ± 88015.833 ops/s |
| jsoniter + binding | 15061063.604 ± 453904.401 ops/s |
| jsoniter + iterator | 26425709.524 ± 333111.069 ops/s |
字段类型是泛型的
如果定义的字段是泛型的,它的值类型可以自动被识别
public class TestObject {
public List<Integer> values;
}
JsonIterator.deserialize("{\"values\":[1,2,3]}", TestObject.class);
如果定义字段的时候类型还是变量,通过子类具体化之后,值类型也是可以知道的
public class SuperClass<E> {
public List<E> values;
}
public class SubClass extends SuperClass<Integer> {
}
JsonIterator.deserialize("{\"values\":[1,2,3]}", SubClass.class);
一个泛型类被具体化有三种办法:
- TypeLiteral
- 通过子类化把变量类型绑定为具体类型
- 直接定义字段类型的时候就指定具体类型参数
如果泛型类对应的参数没法知道,则会用Object.class替代。
接口类型
如果被绑定的类型是一个接口,我们必须选择一个具体的实现类才可以创建出对象来。默认的规则是:
| interface | impl |
|---|---|
| List | ArrayList |
| Set | HashSet |
| Map | HashMap |
其他的接口类型则需要用户来指定了。
JsoniterSpi.registerTypeImplementation(MyInterface.class, MyObject.class);
所有的地方 MyObject.class 都会被用于实例化 MyInterface.class 类型的变量。这个实现关系也可以在 @JsonProperty 上指定。
懒惰是一种美德
需要定义schema来描述数据是一件很麻烦的事情。Jsoniter 允许你把 json 解析为 Any 对象,然后就可以直接使用了。使用体验和 PHP 的 json_decode 差不多。
Lazy 可一点都不慢
给定一个很大的 json 文档
[
// many many more
{
"_id": "58659f976f045f9c69c53efb",
"index": 4,
"guid": "3cbaef3d-25ab-48d0-8807-1974f6aad336",
"isActive": true,
"balance": "$1,854.63",
"picture": "http://placehold.it/32x32",
"age": 26,
"eyeColor": "brown",
"name": "Briggs Larson",
"gender": "male",
"company": "ZOXY",
"email": "[email protected]",
"phone": "+1 (807) 588-3350",
"address": "994 Nichols Avenue, Allamuchy, Guam, 3824",
"about": "Sunt velit ullamco consequat velit ad nisi in sint qui qui ut eiusmod eu. Et ut aliqua mollit cupidatat et proident tempor do est enim exercitation amet aliquip. Non exercitation proident do duis non ullamco do esse dolore in occaecat. Magna ea labore aliqua laborum ad amet est incididunt et quis cillum nulla. Adipisicing veniam nisi esse officia dolor labore. Proident fugiat consequat ullamco fugiat. Est et adipisicing eiusmod excepteur deserunt pariatur aute commodo dolore occaecat veniam dolore.\r\n",
"registered": "2014-07-21T03:28:39 -08:00",
"latitude": -59.741245,
"longitude": -9.657004,
"friends": [
{
"id": 0,
"name": "Herminia Mcknight"
},
{
"id": 1,
"name": "Leann Harding"
},
{
"id": 2,
"name": "Marisol Sykes"
}
],
"tags": [
"ea",
"velit",
"sunt",
"fugiat",
"do",
"Lorem",
"nostrud"
],
"greeting": "Hello, Briggs Larson! You have 3 unread messages.",
"favoriteFruit": "apple"
}
// many many more
]
如果我们用传统的方式来解析,它会被立即解析为 list 和 map 嵌套的结构
List users = (List) iter.read();
int total = 0;
for (Object userObj : users) {
Map user = (Map) userObj;
List friends = (List) user.get("friends");
total += friends.size();
}
return total;
如果使用 Any,则可以延迟被解析
Any users = iter.readAny();
int total = 0;
for (Any user : users) { // 此处触发了数组的解析
total += user.getValue("friends").size(); // 此处触发了对象的解析
}
return total;
是不是延迟解析的,可以用性能评测来验证:
| parsing style | ops/s |
|---|---|
| eager | 48510.942 ± 3891.295 ops/s |
| lazy | 65088.956 ± 5026.304 ops/s |
Any 很容易使用
Any 可以从嵌套的复杂结构里取出深层的值来。而且可以直接读取为你希望的值类型,而不用管实际输入的类型是什么。对的,这个就是给 PHP 抛过来的 json 准备的。
String input = "{'numbers': ['1', '2', ['3', '4']]}".replace('\'', '"');
int value = JsonIterator.deserialize(input).toInt("numbers", 2, 0); // value is 3, converted from string
你可以一行获知你需要的值是传了还没有传,不需要反复 check null
String input = "{'numbers': ['1', '2', ['3', '4']]}".replace('\'', '"');
Any any = JsonIterator.deserialize(input);
Any found = any.get("num", 100); // found is null, so we know it is missing from json
Any 可以作为中间转换层
过去编解码就是在”原始的字节”和”对象”这两个中间做转换。现在我们有了 Any,它可以用作两者之间的中间层次。来看一下这个例子:
List<Any> users = iter.readAny().asList();
Map<String, Any> firstUser = users.get(0).asMap();
HashMap<String, Any> secondUser = new HashMap<>(firstUser);
secondUser.put("name", Any.wrap("fake"));
users.add(1, Any.wrapAnyMap(secondUser));
System.out.println(JsonStream.serialize(users));
首先把输入解码为成员类型为 Any 的 list。然后我们可以对列表进行一些操作,然后我们就可以直接序列化他们。所有在转换过程中没有被碰过的成员的字节会被原样保留,所以这笔把一切都转换为对象然后再处理要快很多。就好像我们直接在对输入字节进行操作一样,从一个 byte array 拷贝到另外一个 byte array。
这里是另外一个例子:
User tom = new User();
tom.index = 1;
tom.name = "tom";
Map<String, Any> tomAsMap = Any.wrap(tom).asMap();
tomAsMap.put("age", Any.wrap(17));
System.out.println(JsonStream.serialize(tomAsMap));
序列化实际上发生了两次。第一次从对象转换成map,然后我们对map进行一些处理,然后map才会转换为字节。所以在你需要的时候,可以把 Any 当成一个处理的中间层次来使用。
Any 的乐趣
修改 Any
Any any = JsonIterator.deserialize("{'numbers': ['1', '2', ['3', '4']]}".replace('\'', '"'));
any.get("numbers").asList().add(Any.wrap("hello"));
assertEquals("{'numbers':['1', '2', ['3', '4'],'hello']}".replace('\'', '"'), JsonStream.serialize(any))
即便路径是不存在的,值也可以被正常提取
any = JsonIterator.deserialize("{'error': 'failed'}".replace('\'', '"')); // not there
assertFalse(any.toBoolean("success"));
any = JsonIterator.deserialize("{'success': true}".replace('\'', '"')); // boolean type
assertTrue(any.toBoolean("success"));
any = JsonIterator.deserialize("{'success': 'false'}".replace('\'', '"')); // string type
assertFalse(any.toBoolean("success"));
一次获得所有数组成员
any = JsonIterator.deserialize("[{'score':100}, {'score':102}]".replace('\'', '"'));
assertEquals("[100,102]", JsonStream.serialize(any.get('*', "score")));
一次获得所有对象成员
any = JsonIterator.deserialize("[{'score':100}, {'score':[102]}]".replace('\'', '"'));
assertEquals("[{},{'score':102}]".replace('\'', '"'), JsonStream.serialize(any.get('*', '*', 0)));
获得原始的值
any = JsonIterator.deserialize("[{'score':100}, {'score':102}]".replace('\'', '"'));
assertEquals(Long.class, any.get(0, "score").object().getClass());
检查路径是否存在
any = JsonIterator.deserialize("[{'score':100}, {'score':102}]".replace('\'', '"'));
assertEquals(ValueType.INVALID, any.get(0, "score", "number").valueType());
流式解析
当输入是很大的json时,我们可能需要使用流式解析的方式来处理。我认为现有的解决方案都很笨拙,这也是我为什么要发明 jsoniter(json iterator) 的初衷。 给定这样的文档,我们想要数一下tag的数量
{
"users": [
{
"_id": "58451574858913704731",
"about": "a4KzKZRVvqfBLdnpUWaD",
"address": "U2YC2AEVn8ab4InRwDmu",
"age": 27,
"balance": "I5cZ5vRPmVXW0lhhRzF4",
"company": "jwLot8sFN1hMdE4EVW7e",
"email": "30KqJ0oeYXLqhKMLDUg6",
"eyeColor": "RWXrMsO6xi9cpxPqzJA1",
"favoriteFruit": "iyOuAekbybTUeDJqkHNI",
"gender": "ytgB3Kzoejv1FGU6biXu",
"greeting": "7GXmN2vMLcS2uimxGQgC",
"guid": "bIqNIywgrzva4d5LfNlm",
"index": 169390966,
"isActive": true,
"latitude": 70.7333712683406,
"longitude": 16.25873969455544,
"name": "bvtukpT6dXtqfbObGyBU",
"phone": "UsxtI7sWGIEGvM2N1Mh0",
"picture": "8fiyZ2oKapWtH5kXyNDZJjvRS5PGzJGGxDCAk1he1wuhUjxfjtGIh6agQMbjovF10YlqOyzhQPCagBZpW41r6CdrghVfgtpDy7YH",
"registered": "gJDieuwVu9H7eYmYnZkz",
"tags": [
"M2b9n0QrqC",
"zl6iJcT68v",
"VRuP4BRWjs",
"ZY9jXIjTMR"
]
}
]
}
Tokenizer 的 api 很难用
java 官方的 https://jsonp.java.net/ 就别提了,简直糟糕头顶。它甚至没有方法可以直接skip掉一个值。Jackson是我唯一可以找到尚可一用的实现:
public int calc(JsonParser jParser) throws IOException {
int totalTagsCount = 0;
while (jParser.nextToken() != com.fasterxml.jackson.core.JsonToken.END_OBJECT) {
String fieldname = jParser.getCurrentName();
if ("users".equals(fieldname)) {
while (jParser.nextToken() != com.fasterxml.jackson.core.JsonToken.END_ARRAY) {
totalTagsCount += jacksonUser(jParser);
}
}
}
return totalTagsCount;
}
private int jacksonUser(JsonParser jParser) throws IOException {
int totalTagsCount = 0;
while (jParser.nextToken() != com.fasterxml.jackson.core.JsonToken.END_OBJECT) {
String fieldname = jParser.getCurrentName();
switch (fieldname) {
case "tags":
jParser.nextToken();
while (jParser.nextToken() != com.fasterxml.jackson.core.JsonToken.END_ARRAY) {
totalTagsCount++;
}
break;
default:
jParser.nextToken();
jParser.skipChildren();
}
}
return totalTagsCount;
}
咋一看,还不错。问题是 tokenizer 给你了 token,你需要负责写出完备地处理逻辑。如果处理的形况没有写全,出错了则很难调试。这样就被迫需要没拿到一个token都判断所有可能的情况。
Iterator 简单明了
同样的逻辑使用 jsoniter 的 iterator-api 来实现:
public int calc(JsonIterator iter) throws IOException {
int totalTagsCount = 0;
for (String field = iter.readObject(); field != null; field = iter.readObject()) {
switch (field) {
case "users":
while (iter.readArray()) {
for (String field2 = iter.readObject(); field2 != null; field2 = iter.readObject()) {
switch (field2) {
case "tags":
while (iter.readArray()) {
iter.skip();
totalTagsCount++;
}
break;
default:
iter.skip();
}
}
}
break;
default:
iter.skip();
}
}
return totalTagsCount;
}
如果我们把输入从数组变成对象
{
"users": [
{
// ...
"tags": {
"tag1": "M2b9n0QrqC",
"tag2": "zl6iJcT68v",
"tag3": "VRuP4BRWjs",
"tag4": "ZY9jXIjTMR"
}
}
]
}
出错的消息立马可以知道是什么原因:
com.jsoniter.JsonException: readArray: expect [ or , or n or ], but found: {, head: 1010, peek: "tags": {, buf: {
Service Provider Interface (SPI)
扩展性是从第一天就考虑进来的事情。我很讨厌一堆特性开关的模式。如果可能话,优先提供的以回调接口的方式来扩展。核心功能尽可能地最小化。如果用户侧可以自己控制的事情,则不会考虑在库里面提供类似的功能。如果新增一个功能会导致所有人的性能下降,则不会增加。
整体架构
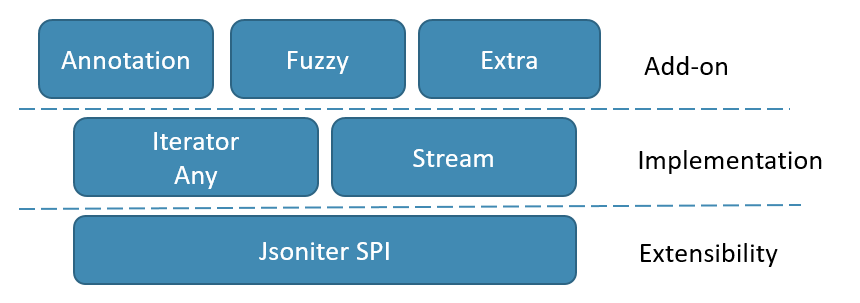
Jsoniter的架构分为3层:
- 最底层的抽象是 service provider interface。它定义了 Encoder/Decoder 和 ClassDescriptor 这样的东西。
- 核心部分是实现代码。Stream 实现了编码部分,它不应该引用任何 Iterator/Any 相关的东西。Iterator/Any 实现了解码,iterator 是只能前向的,而 Any 则在 iterator 外面包了一层,提供随机访问的特性。
- 最上面的是一些附加功能。特别值得一提的是 annotation 的支持是这层来提供的。所有 annotation 支持的功能,你都可以用 SPI 来自己实现。甚至有一个 Jackson annotation 的兼容实现,可以在不改现有 Model 的前提复用 Jackson 的 annotation。
这里只是快速演示一下 SPI 都可以完成哪些事情。具体的,请直接阅读源代码。
不用 Extension 就可以扩展
什么都可以用 Extension 实现。但是,也有一些捷径可走
- registerTypeDecoder: 指定一个类型的解码方式
- registerPropertyDecoder: 指定某个类的某个字段的解码方式
- registerTypeEncoder: 指定一个类型的编码方式
- registerPropertyEncoder: 指定某个类的某个字段的编码方式
- registerTypeImplementation: 选择抽象类或者接口的具体实现类
什么都能用 Extension 自定义
public interface Extension {
Type chooseImplementation(Type type);
boolean canCreate(Class clazz);
Object create(Class clazz);
Decoder createDecoder(String cacheKey, Type type);
Encoder createEncoder(String cacheKey, Type type);
void updateClassDescriptor(ClassDescriptor desc);
}
你可以定制
- 类型的编解码方式,类似于 registerTypeEncoder, registerTypeDecoder
- 控制对象实例的创建方式,比如和你最喜欢的依赖注入工具相结合
- 选择实现类,类似于 registerTypeImplementation
- updateClassDescriptor,这个下面详细讲
public class ClassDescriptor {
public Class clazz;
public Map<String, Type> lookup;
public ConstructorDescriptor ctor;
public List<Binding> fields;
public List<Binding> setters;
public List<Binding> getters;
public List<WrapperDescriptor> wrappers;
public List<Method> unWrappers;
public boolean asExtraForUnknownProperties;
public Binding onMissingProperties;
public Binding onExtraProperties;
}
Class descriptor 是一个中间描述。它夹在编解码的实现(无论是codegen还是反射模式均支持)与实际的对象结构之间。例如,重命名一个字段可以通过修改 fields List<Binding> 来实现。
public class Binding {
// input
public final Class clazz;
public final TypeLiteral clazzTypeLiteral;
public Annotation[] annotations;
public Field field; // obj.XXX
public Method method; // obj.setXXX() or obj.getXXX()
public boolean valueCanReuse;
// input/output
public String name;
public Type valueType;
public TypeLiteral valueTypeLiteral;
// output
public String[] fromNames; // for decoder
public String[] toNames; // for encoder
public Decoder decoder;
public Encoder encoder;
public boolean asMissingWhenNotPresent;
public boolean asExtraWhenPresent;
public boolean isNullable = true;
public boolean isCollectionValueNullable = true;
public boolean shouldOmitNull = true;
// then this property will not be unknown
// but we do not want to bind it anywhere
public boolean shouldSkip;
// attachment, used when generating code or reflection
public int idx;
public long mask;
}
通过设置 fromNames 或者 toNames,我们可以改变字段与 JSON 的对应关系。所有 annotation 支持的特性,都可以用 extension 来实现。也就是说,不用修改类定义,你也可以修改各种对象绑定的行为。
在 “extra” 包中有一些预定义好的 extension:
- Base64Support
- JdkDatetimeSupport
- NamingStrategySupport
- PreciseFloatSupport
虽然在核心实现里没有预埋很多的特性开关,通过 extension 我们仍然可以提供相同的功能,而且性能方面也没有妥协。