Machine Used:
- CPU: i7-4790 @ 3.6G
- Memory: 16G
Java Bind API
- JMH 1.17.1 (released 11 days ago)
- VM version: JDK 1.8.0_112, VM 25.112-b15
- VM invoker: /opt/jdk1.8.0_112/jre/bin/java
- VM options: -XX:+AggressiveOpts -Xms2G -Xmx2G
- Warmup: 3 iterations, 1 s each
- Measurement: 5 iterations, 2 s each
- Timeout: 10 min per iteration
- Threads: 16 threads, will synchronize iterations
- Benchmark mode: Throughput, ops/time
https://github.com/json-iterator/java-benchmark
| scenario | Protobuf V.S. Jackson | Protobuf V.S. Jsoniter | Jsoniter V.S Jackson |
|---|---|---|---|
| Decode Integer | 8.51 | 2.64 | 3.22 |
| Encode Integer | 2.9 | 1.44 | 2.02 |
| Decode Double | 13.75 | 4.4 | 3.13 |
| Encode Double | 12.71 | 1.96 (only 6 digits precision) | 6.5 |
| Decode Object | 1.22 | 0.6 | 2.04 |
| Encode Object | 1.72 | 0.67 | 2.59 |
| Decode Integer List | 2.92 | 0.98 | 2.97 |
| Encode Integer List | 1.35 | 0.71 | 1.9 |
| Decode Object List | 1.26 | 0.43 | 2.91 |
| Encode Object List | 2.22 | 0.61 | 3.63 |
| Decode Double Array | 5.18 | 1.47 | 3.52 |
| Encode Double Array | 15.63 | 2.32 (only 6 digits precision) | 6.74 |
| Decode String | 1.85 | 0.77 | 2.4 |
| Encode String | 0.96 | 0.63 | 1.5 |
| Skip Structure | 5.05 | 1.35 | 3.75 |
Go Bind API
Different libraries bind data to struct in different ways:
- encoding/json: reflection
- easyjson: go generate
- jsonparser: hand-written data bind
- jsoniter (iterator-api): hand-written data bind
- jsoniter (bind-api): reflection
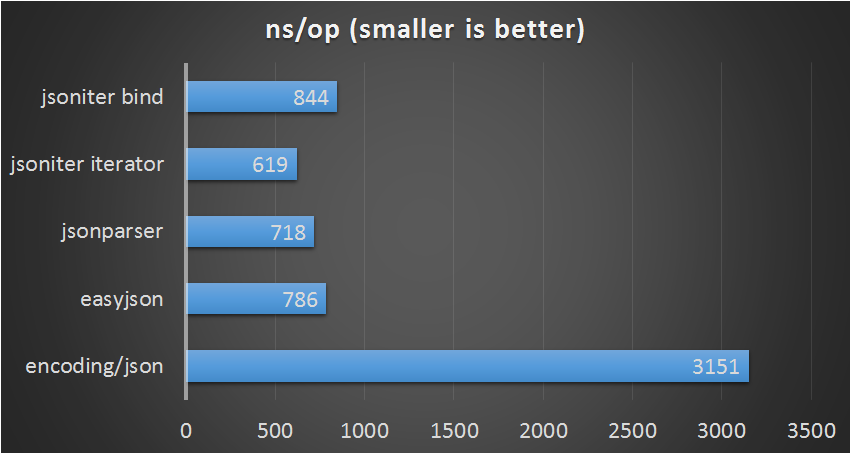
Small Payload
bind small payload of json to struct
| parser | ns/op | bytes/op | allocs/op |
|---|---|---|---|
| encoding/json | 3151 ns/op | 480 B/op | 6 allocs/op |
| easyjson | 786 ns/op | 64 B/op | 2 allocs/op |
| jsonparser | 718 ns/op | 64 B/op | 2 allocs/op |
| jsoniter (iterator-api) | 619 ns/op | 64 B/op | 2 allocs/op |
| jsoniter (bind-api) | 844 ns/op | 256 B/op | 4 allocs/op |
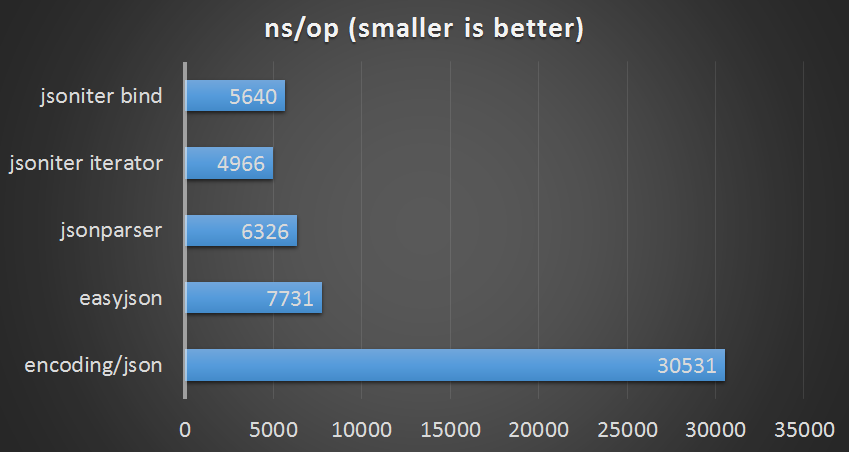
Medium Payload
bind medium payload of json to nested struct
| parser | ns/op | bytes/op | allocs/op |
|---|---|---|---|
| encoding/json | 30531 ns/op | 808 B/op | 18 allocs/op |
| easyjson | 7731 ns/op | 248 B/op | 8 allocs/op |
| jsonparser | 6326 ns/op | 104 B/op | 4 allocs/op |
| jsoniter (iterator-api) | 4966 ns/op | 104 B/op | 4 allocs/op |
| jsoniter (bind-api) | 5640 ns/op | 368 B/op | 14 allocs/op |
Go Iterator API
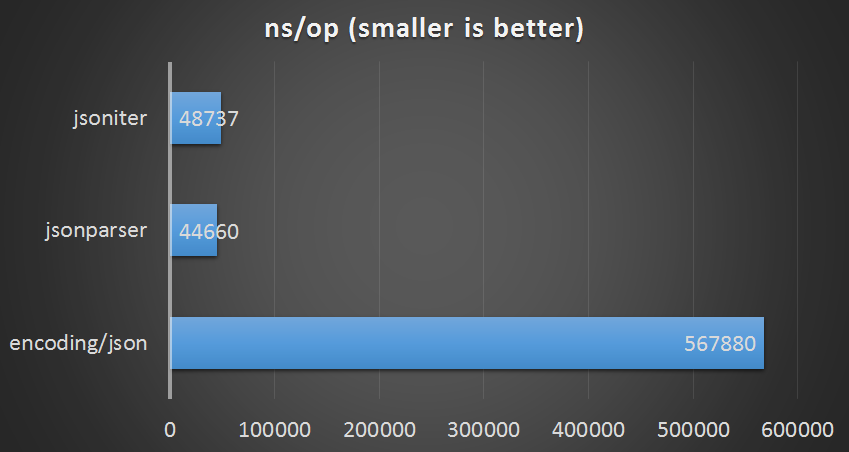
Large Payload
count number of elements from []byte without binding
| parser | ns/op | bytes/op | allocs/op |
|---|---|---|---|
| encoding/json | 567880 ns/op | 79177 B/op | 4918 allocs/op |
| jsonparser | 44660 ns/op | 0 B/op | 0 allocs/op |
| jsoniter (iterator-api) | 48737 ns/op | 0 B/op | 0 allocs/op |
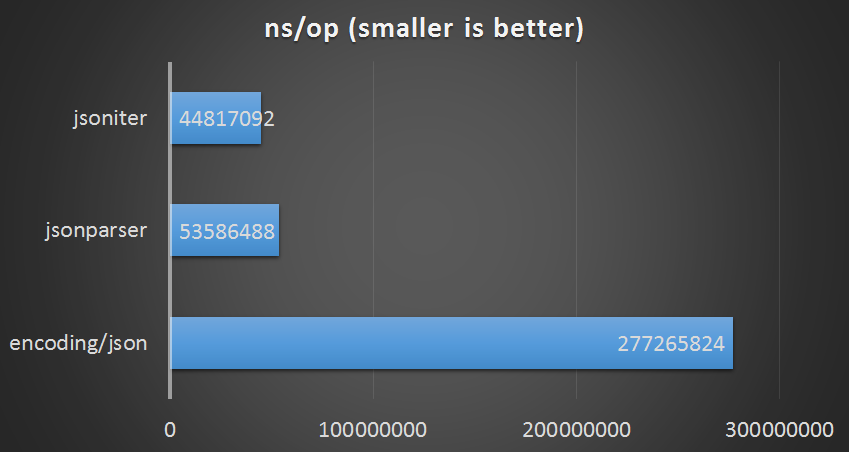
Large File
count number of elements from io.Reader without binding
| parser | ns/op | bytes/op | allocs/op |
|---|---|---|---|
| encoding/json | 277265824 ns/op | 71467156 B/op | 272476 allocs/op |
| jsonparser | 53586488 ns/op | 67107204 B/op | 20 allocs/op |
| jsoniter (iterator-api) | 44817092 ns/op | 4248 B/op | 5 allocs/op |
Optimization used
Single pass scan
All parsing is done within one pass directly from byte array stream. Single pass has two level of meaning:
- on the large scale: the iterator api is forward only, you get what you need from current spot. There is no going back.
- on the micro scale: readInt or readString is done in one pass. For example, parse integer is not done by cutting string out, then parse string. Instead we use the byte stream to calculate int value directly. even readFloat or readDouble is implemented this way, with exceptions.
Minimum allocation
Making copy is avoided at all necessary means. For example, the parser has a internal byte array buffer holding recent byte. When parsing the field name of object, we do not allocate new bytes to hold field name. Instead, if possible, the buffer is reused as slice.
Iterator instance itself keep copy of all kinds of buffer it used, and they can be reused by reset iterator with new input instead of create brand new iterator.
Pull from stream
The input can be a InputStream or io.Reader, we do not read all bytes out into a big array. Instead the parsing is done in chunks. When we need more, we pull from the stream.
Take string seriously
String parsing is performance killer if not being handled properly. The trick I learned from jsonparser and dsljson is taking a fast path for string without escape character.
For golang, the string is utf-8 bytes based. The fastest way to construct a string is direct cast from []byte to string, if you can make ensure the []byte does not go away or being modified.
For java, the string is utf-16 char based. Parsing utf8 byte stream to utf16 char array is done by the parser directly, instead of using UTF8 charset. The cost of construct string, is simplely a char array copy.
Schema based
Iterator api is active instead of passive compared to tokenizer api. It does not parse the token out, then if branching. Instead, given the schema, we know exactly what is ahead of us, so we just parse them as what we think it should be. If input disagree, then we raise proper error.
Skip takes different path
Skip an object or array should take different path learned from jsonparser. We do not care about nested field name or so when we are skipping a whole object.
Table lookup
Some calculation such as what is int value for char ‘5’ can be done ahead of time.
Java only optimization
Java parser is dynamically generated using javassist. Because we are actually generating real java source code, the generator can be easily implemented as static annotation processor.
Since the source code is generated, we are not afraid of making it tedious but specific:
public Object decode(java.lang.reflect.Type type, com.jsoniter.Jsoniter iter) {
com.jsoniter.SimpleObject obj = new com.jsoniter.SimpleObject();
for (com.jsoniter.Slice field = iter.readObjectAsSlice(); field != null; field = iter.readObjectAsSlice()) {
switch (field.len) {
case 6:
if (field.at(0)==102) {
if (field.at(1)==105) {
if (field.at(2)==101) {
if (field.at(3)==108) {
if (field.at(4)==100) {
if (field.at(5)==49) {
obj.field1 = iter.readString();
continue;
}
if (field.at(5)==50) {
obj.field2 = iter.readString();
continue;
}
}
}
}
}
}
break;
}
iter.skip();
}
return obj;
}
}
Also this:
public Object decode(java.lang.reflect.Type type, com.jsoniter.Jsoniter iter) {
if (!iter.readArray()) {
return new int[0];
}
int a1 = iter.readInt();
if (!iter.readArray()) {
return new int[]{ a1 };
}
int a2 = iter.readInt();
if (!iter.readArray()) {
return new int[]{ a1, a2 };
}
int a3 = iter.readInt();
if (!iter.readArray()) {
return new int[]{ a1, a2, a3 };
}
int a4 = (int) iter.readInt();
int[] arr = new int[8];
arr[0] = a1;
arr[1] = a2;
arr[2] = a3;
arr[3] = a4;
int i = 4;
while (iter.readArray()) {
if (i == arr.length) {
int[] newArr = new int[arr.length * 2];
System.arraycopy(arr, 0, newArr, 0, arr.length);
arr = newArr;
}
arr[i++] = iter.readInt();
}
int[] result = new int[i];
System.arraycopy(arr, 0, result, 0, i);
return result;
}
}
Golang only optimization
binding to object is not using reflect api. Instead the raw pointer is taken out of interface{}, then cast to proper pointer type to set value. For example:
*((*int)(ptr)) = iter.ReadInt()
Another optimization is we know how many fields are parsing out for a struct, so we can write the field dispatch differently. For no field, we simply skip. For one field, if/else is enough. 2~4 fields switch case. 5 or more fields, we fallback to use map based field dispatching.
Golang version is not using go generate as I find it unfriendly to new developer. I might add go generate as an option and put same optimization I did for java version. It can be faster. Being able to access the raw pointer, the golang data binding performance is already good enough. As we can see from the benchmark, hand rolled binding code is only a little faster. This case might change, if golang decided to close it’s memory layout for direct manipulation, or there is JIT can optimize more if we can get rid of pointer chasing introduced by virtual method.